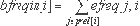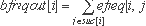Реализация метода маскировки
В данном разделе мы рассмотрим более детально круг вопросов, связанных с реализацией предложенного метода маскировки ММ. В качестве среды реализации используется интегрированная среда Poirot.
Напомним основные обозначения, введённые ранее. Инструкции, составляющие тело функции, находятся в массиве instr, индексируемом от 0 и до Ninstr-1, где Ninstr - общее количество инструкций в теле функции. Первая инструкция в этом массиве - инструкция FUNC - пролог функции в представлении MIF, последняя инструкция - инструкция END - эпилог функции. Пусть B - массив базовых блоков этой функции, пусть для каждого базового блока i succ[i] - множество следующих за ним базовых блоков, а pred[i] - множество предшествующих ему базовых блоков, first[i] - номер первой инструкции в массиве instr, принадлежащей базовому блоку i, last[i] - номер последней инструкции в массиве instr, принадлежащей базовому блоку i, nbinstr[i] - количество инструкций в базовом блоке i. Информация о доминировании представлена для каждого блока i номером его непосредственного доминатора idom[i] и номером его непосредственного постдоминатора ipdom[i].
Информация о потоке данных программы представлена в виде ud- и du-множеств. Для аргумента j инструкции с номером i в теле функции ud[i,j] - это множество пар , в которых может модифицироваться переменная, и которые достигают данной точки функции. С другой стороны du[i,j] - это множество пар , в которых может использоваться переменная, и которые достижимы из данной точки функции.
В ud- и du-множествах также отражается собранная информация об алиасах. Для сбора информации об алиасах можно использовать понятие абстрактной области памяти. Абстрактная область памяти - именованная ячейка, доступ к которой возможен из программы одним или несколькими способами. Множество абстрактных ячеек памяти - вся память, с которой может манипулировать программа, с точки зрения алгоритма анализа алиасов. От детальности множества абстрактных ячеек памяти зависит точность выявленных указателей.
С другой стороны, чем детальнее множество абстрактных ячеек памяти, тем больше ресурсов требуется для выполнения анализа алиасов. Простейшее по структуре множество абстрактных ячеек памяти включает в себя имена всех локальных и глобальных переменных, а также специальный символ anon, обозначающий динамическую память. Здесь не делается попытки детализации структурных и массивовых типов, различения различных рекурсивных вызовов одной и той же функции, а также детализации структуры данных в динамической области.
Для каждой переменной указательного типа поддерживается множество абстрактных ячеек памяти, на которые может указывать данная переменная. Если переменная имеет кратный указательный тип, глубина разыменования указателя может быть ограничена. Обработка множества АЯП для объектов структурных и массивовых типов зависит от детальности множества АЯП. В простейшем случае, когда поля структур и элементы массивов не различаются, объект структурного или массивового типа считается указателем, если он содержит хотя бы одно поле указательного типа. Множество АЯП, на которые может указывать такой объект получается объединением всех множеств АЯП, на которые могут указывать поля структуры или элементы массива.
Информация об алиасах вычисляется с помощью стандартных алгоритмов анализа алиасов, например, описанных в [16]. После того, как для каждого указателя и для каждой точки программы вычислено множество абстрактных ячеек памяти, на которые он может указывать, эта информация переносится в ud- и du-множества. Например, если некоторая переменная v присутствует в множестве абстрактных ячеек памяти указателя p, то чтение по указателю p включается в du-цепочку переменной v, если последняя инструкция достижима из точки присваивания. В результате анализа алиасов может оказаться, что точности алгоритма недостаточно, и что множество абстрактных ячеек памяти, адресуемых некоторым указателем в некоторой точке программы, состоит из всех абстрактных ячеек памяти.
Другую сложность представляют вызовы функций.
Для выявления влияния функции на своё окружение требуется межпроцедурный анализ, являющийся весьма трудоёмким. Поэтому желательно ограничиться минимальным консервативным анализом, который исходит из следующих предположений:
Любая функция читает и изменяет все глобальные переменные.
Любая функция пытается разыменовывать любой указатель, переданный ей в качестве параметра.
После выполнения любой функции все глобальные указатели могут указывать на любые глобальные объекты, любые локальные объекты, упомянутые среди абстрактных ячеек памяти указателей-параметров, и на область динамической памяти.
Любая функция модифицирует все абстрактные ячейки памяти, на которые могут указывать указатели, переданные ей в качестве параметра.
Если среди таких абстрактных ячеек памяти есть локальные переменные указательного типа, то после выполнения функции они могут указывать на любой глобальный объект, любой локальный объект, упомянутый среди абстрактных ячеек памяти указателей-параметров функции, и на область динамической памяти.
Если функция возвращает значение указательного типа, это значение может указывать на любой глобальный объект, любой локальный объект, упомянутый среди абстрактных ячеек памяти указателей-параметров функции, и на область динамической памяти.
Современные языки содержат средства, позволяющие при объявлении функции уточнить степень влияния этой функции на окружение программы. К таким средствам относятся, например, квалификаторы типа const и restrict языка Си.
Указанные выше правила определения побочного эффекта функции отражаются на вычислении du- и ud-множеств в случае вызова функции. Дальнейшие шаги метода ММ работают с du- и ud-цепочками и не анализируют множества абстрактных ячеек памяти.
Метод ММ может использовать информацию о частотах выполнения дуг графа потока управления функции, полученную в результате профилирования. Каждой дуге графа потока управления ставится в соответствие число прохождений по ней. Поскольку каждая дуга графа потока управления однозначно идентифицируется парой номеров базовых блоков откуда она выходит и куда входит, предположим, что все частоты прохождения дуг хранятся в двумерном массиве efreq.Число efreq[i,j] равно количеству прохождений дуги B[i]->B[j]. Если такой дуги в графе потока управления не существует, положим число прохождений равным нулю. Пусть также